 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGranite Embedding Multilingual R2 Models
May 13, 2026We introduce the multilingual Granite Embedding R2 models, a family of encoder-based embedding models for enterprise-scale dense retrieval across 200+ languages. Extending our English-focused R2 release, these models add enhanced support for 52 languages and programming code, a 32,768-token context window (a 64x expansion over R1), and state-of-the-art overall performance across multilingual and cross-lingual text search, code retrieval, long-document search, and reasoning retrieval datasets. The release consists of two bi-encoder models based on the ModernBERT architecture with an expanded multilingual vocabulary: a 311M-parameter full-size, and a 97M-parameter compact model built via model pruning and vocabulary selection that achieves the highest retrieval score of any open multilingual embedding model under 100M parameters. The full-size also supports Matryoshka Representation Learning for flexible embedding dimensionality. Both models are trained on enterprise-appropriate data with governance oversight, and released under the Apache 2.0 license at https://huggingface.co/collections/ibm-granite, designed to support responsible use and enable unrestricted research and enterprise adoption.
LMK > CLS: Landmark Pooling for Dense Embeddings
Jan 29, 2026Representation learning is central to many downstream tasks such as search, clustering, classification, and reranking. State-of-the-art sequence encoders typically collapse a variable-length token sequence to a single vector using a pooling operator, most commonly a special [CLS] token or mean pooling over token embeddings. In this paper, we identify systematic weaknesses of these pooling strategies: [CLS] tends to concentrate information toward the initial positions of the sequence and can under-represent distributed evidence, while mean pooling can dilute salient local signals, sometimes leading to worse short-context performance. To address these issues, we introduce Landmark (LMK) pooling, which partitions a sequence into chunks, inserts landmark tokens between chunks, and forms the final representation by mean-pooling the landmark token embeddings. This simple mechanism improves long-context extrapolation without sacrificing local salient features, at the cost of introducing a small number of special tokens. We empirically demonstrate that LMK pooling matches existing methods on short-context retrieval tasks and yields substantial improvements on long-context tasks, making it a practical and scalable alternative to existing pooling methods.
Optimal Policy Minimum Bayesian Risk
May 22, 2025Inference scaling can help LLMs solve complex reasoning problems through extended runtime computation. On top of targeted supervision for long chain-of-thought (long-CoT) generation, purely inference-time techniques such as best-of-N (BoN) sampling, majority voting, or more generally, minimum Bayes risk decoding (MBRD), can further improve LLM accuracy by generating multiple candidate solutions and aggregating over them. These methods typically leverage additional signals in the form of reward models and risk/similarity functions that compare generated samples, e.g., exact match in some normalized space or standard similarity metrics such as Rouge. Here we present a novel method for incorporating reward and risk/similarity signals into MBRD. Based on the concept of optimal policy in KL-controlled reinforcement learning, our framework provides a simple and well-defined mechanism for leveraging such signals, offering several advantages over traditional inference-time methods: higher robustness, improved accuracy, and well-understood asymptotic behavior. In addition, it allows for the development of a sample-efficient variant of MBRD that can adjust the number of samples to generate according to the difficulty of the problem, without relying on majority vote counts. We empirically demonstrate the advantages of our approach on math (MATH-$500$) and coding (HumanEval) tasks using recent open-source models. We also present a comprehensive analysis of its accuracy-compute trade-offs.
Granite Embedding Models
Feb 27, 2025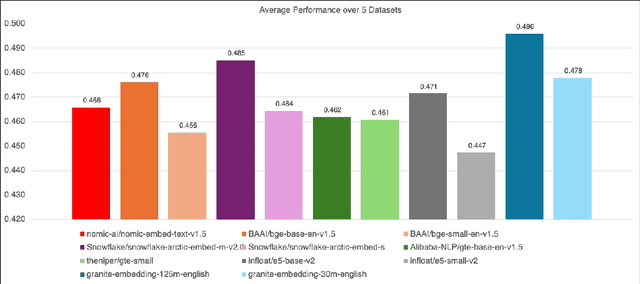
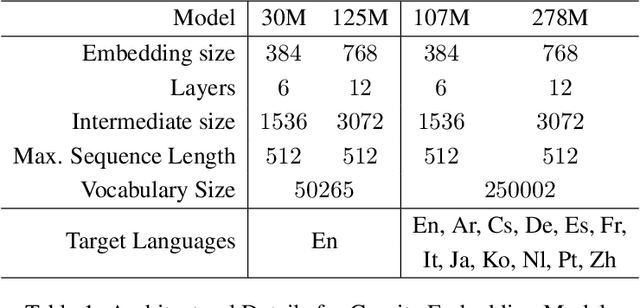
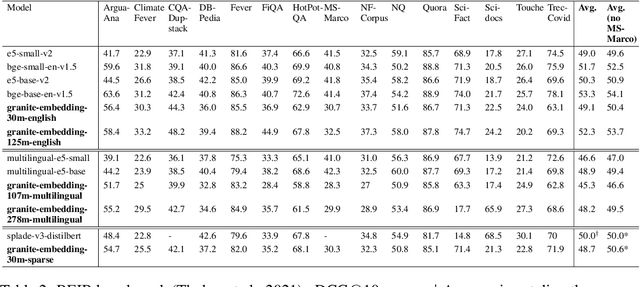

We introduce the Granite Embedding models, a family of encoder-based embedding models designed for retrieval tasks, spanning dense-retrieval and sparse retrieval architectures, with both English and Multilingual capabilities. This report provides the technical details of training these highly effective 12 layer embedding models, along with their efficient 6 layer distilled counterparts. Extensive evaluations show that the models, developed with techniques like retrieval oriented pretraining, contrastive finetuning, knowledge distillation, and model merging significantly outperform publicly available models of similar sizes on both internal IBM retrieval and search tasks, and have equivalent performance on widely used information retrieval benchmarks, while being trained on high-quality data suitable for enterprise use. We publicly release all our Granite Embedding models under the Apache 2.0 license, allowing both research and commercial use at https://huggingface.co/collections/ibm-granite.
INDUS: Effective and Efficient Language Models for Scientific Applications
May 17, 2024



Large language models (LLMs) trained on general domain corpora showed remarkable results on natural language processing (NLP) tasks. However, previous research demonstrated LLMs trained using domain-focused corpora perform better on specialized tasks. Inspired by this pivotal insight, we developed INDUS, a comprehensive suite of LLMs tailored for the Earth science, biology, physics, heliophysics, planetary sciences and astrophysics domains and trained using curated scientific corpora drawn from diverse data sources. The suite of models include: (1) an encoder model trained using domain-specific vocabulary and corpora to address natural language understanding tasks, (2) a contrastive-learning-based general text embedding model trained using a diverse set of datasets drawn from multiple sources to address information retrieval tasks and (3) smaller versions of these models created using knowledge distillation techniques to address applications which have latency or resource constraints. We also created three new scientific benchmark datasets namely, CLIMATE-CHANGE-NER (entity-recognition), NASA-QA (extractive QA) and NASA-IR (IR) to accelerate research in these multi-disciplinary fields. Finally, we show that our models outperform both general-purpose encoders (RoBERTa) and existing domain-specific encoders (SciBERT) on these new tasks as well as existing benchmark tasks in the domains of interest.
Detectors for Safe and Reliable LLMs: Implementations, Uses, and Limitations
Mar 09, 2024



Large language models (LLMs) are susceptible to a variety of risks, from non-faithful output to biased and toxic generations. Due to several limiting factors surrounding LLMs (training cost, API access, data availability, etc.), it may not always be feasible to impose direct safety constraints on a deployed model. Therefore, an efficient and reliable alternative is required. To this end, we present our ongoing efforts to create and deploy a library of detectors: compact and easy-to-build classification models that provide labels for various harms. In addition to the detectors themselves, we discuss a wide range of uses for these detector models - from acting as guardrails to enabling effective AI governance. We also deep dive into inherent challenges in their development and discuss future work aimed at making the detectors more reliable and broadening their scope.
Efficient Models for the Detection of Hate, Abuse and Profanity
Feb 08, 2024



Large Language Models (LLMs) are the cornerstone for many Natural Language Processing (NLP) tasks like sentiment analysis, document classification, named entity recognition, question answering, summarization, etc. LLMs are often trained on data which originates from the web. This data is prone to having content with Hate, Abuse and Profanity (HAP). For a detailed definition of HAP, please refer to the Appendix. Due to the LLMs being exposed to HAP content during training, the models learn it and may then generate hateful or profane content. For example, when the open-source RoBERTa model (specifically, the RoBERTA base model) from the HuggingFace (HF) Transformers library is prompted to replace the mask token in `I do not know that Persian people are that MASK` it returns the word `stupid` with the highest score. This is unacceptable in civil discourse.The detection of Hate, Abuse and Profanity in text is a vital component of creating civil and unbiased LLMs, which is needed not only for English, but for all languages. In this article, we briefly describe the creation of HAP detectors and various ways of using them to make models civil and acceptable in the output they generate.
An Empirical Investigation into the Effect of Parameter Choices in Knowledge Distillation
Jan 12, 2024



We present a large-scale empirical study of how choices of configuration parameters affect performance in knowledge distillation (KD). An example of such a KD parameter is the measure of distance between the predictions of the teacher and the student, common choices for which include the mean squared error (MSE) and the KL-divergence. Although scattered efforts have been made to understand the differences between such options, the KD literature still lacks a systematic study on their general effect on student performance. We take an empirical approach to this question in this paper, seeking to find out the extent to which such choices influence student performance across 13 datasets from 4 NLP tasks and 3 student sizes. We quantify the cost of making sub-optimal choices and identify a single configuration that performs well across the board.
Muted: Multilingual Targeted Offensive Speech Identification and Visualization
Dec 18, 2023



Offensive language such as hate, abuse, and profanity (HAP) occurs in various content on the web. While previous work has mostly dealt with sentence level annotations, there have been a few recent attempts to identify offensive spans as well. We build upon this work and introduce Muted, a system to identify multilingual HAP content by displaying offensive arguments and their targets using heat maps to indicate their intensity. Muted can leverage any transformer-based HAP-classification model and its attention mechanism out-of-the-box to identify toxic spans, without further fine-tuning. In addition, we use the spaCy library to identify the specific targets and arguments for the words predicted by the attention heatmaps. We present the model's performance on identifying offensive spans and their targets in existing datasets and present new annotations on German text. Finally, we demonstrate our proposed visualization tool on multilingual inputs.
A Comparative Analysis of Task-Agnostic Distillation Methods for Compressing Transformer Language Models
Oct 13, 2023



Large language models have become a vital component in modern NLP, achieving state of the art performance in a variety of tasks. However, they are often inefficient for real-world deployment due to their expensive inference costs. Knowledge distillation is a promising technique to improve their efficiency while retaining most of their effectiveness. In this paper, we reproduce, compare and analyze several representative methods for task-agnostic (general-purpose) distillation of Transformer language models. Our target of study includes Output Distribution (OD) transfer, Hidden State (HS) transfer with various layer mapping strategies, and Multi-Head Attention (MHA) transfer based on MiniLMv2. Through our extensive experiments, we study the effectiveness of each method for various student architectures in both monolingual (English) and multilingual settings. Overall, we show that MHA transfer based on MiniLMv2 is generally the best option for distillation and explain the potential reasons behind its success. Moreover, we show that HS transfer remains as a competitive baseline, especially under a sophisticated layer mapping strategy, while OD transfer consistently lags behind other approaches. Findings from this study helped us deploy efficient yet effective student models for latency-critical applications.